881.neutron_s
Physics simulation of neutron transport in nuclear reactors
John Tramm <jtramm[at]anl [dot] gov>
881.neutron was submitted to the SPEC CPU v8 Benchmark Search Program by John Tramm.
Neutron is the union of XSBench and RSBench, two mini-apps that solve a problem with neutron transport in nuclear reactor physics. They tackle the same high level problem, albeit in two different ways. A high level summary is that XSBench retains data in memory and is memory intensive whereas RSBench computes the data, is less memory intensive but more computationally intensive. Both are relevant for modern nuclear physics simulations. A description and comparison of both algorithms is below.
The XSBench mini-application models the most computationally intensive part of a typical Monte Carlo (MC) neutron transport nuclear reactor core transport simulation, the calculation of macroscopic neutron cross sections from point-wise data. This is a kernel which accounts for up to 85% of the total runtime of production MC applications like OpenMC. XSBench retains the essential performance-related computational conditions and tasks of fully featured reactor core MC neutron transport codes, yet at a fraction of the programming complexity of the full application. XSBench provides a much simpler and far more transparent platform for testing the algorithm on different architectures, making alterations to the code, and collecting hardware runtime performance data.
XSBench has been used for over a decade in the HPC field both to study the MC algorithm and to also serve as a memory intensive benchmark application for evaluating the performance of new system architectures. The original publication on XSBench has been cited 184 times as a result of its use as a benchmark in a wide variety of computer science compiler development and hardware design research.
RSBench accomplishes the same computational task as XSBench, but uses a totally different way of representing cross section data. XSBench uses very large tabulated point-wise data tables that need to be searched through to assemble macroscopic cross sections. RSBench, on the other hand, utilizes a newer "multipole" representation that stores the quantum mechanical resonance data directly, leading to a several orders of magnitude of data compression at the cost of the need to mathematically evaluate cross section data on-the-fly. In effect, the methods employed in RSBench result in significant memory footprint and bandwidth savings at the cost of greatly increased usage of floating point arithmetic. While XSBench is typically a purely memory bound algorithm, the methods employed in RSBench can sometimes result in the algorithm becoming compute limited instead of bandwidth limited, which may be highly advantageous on some systems.
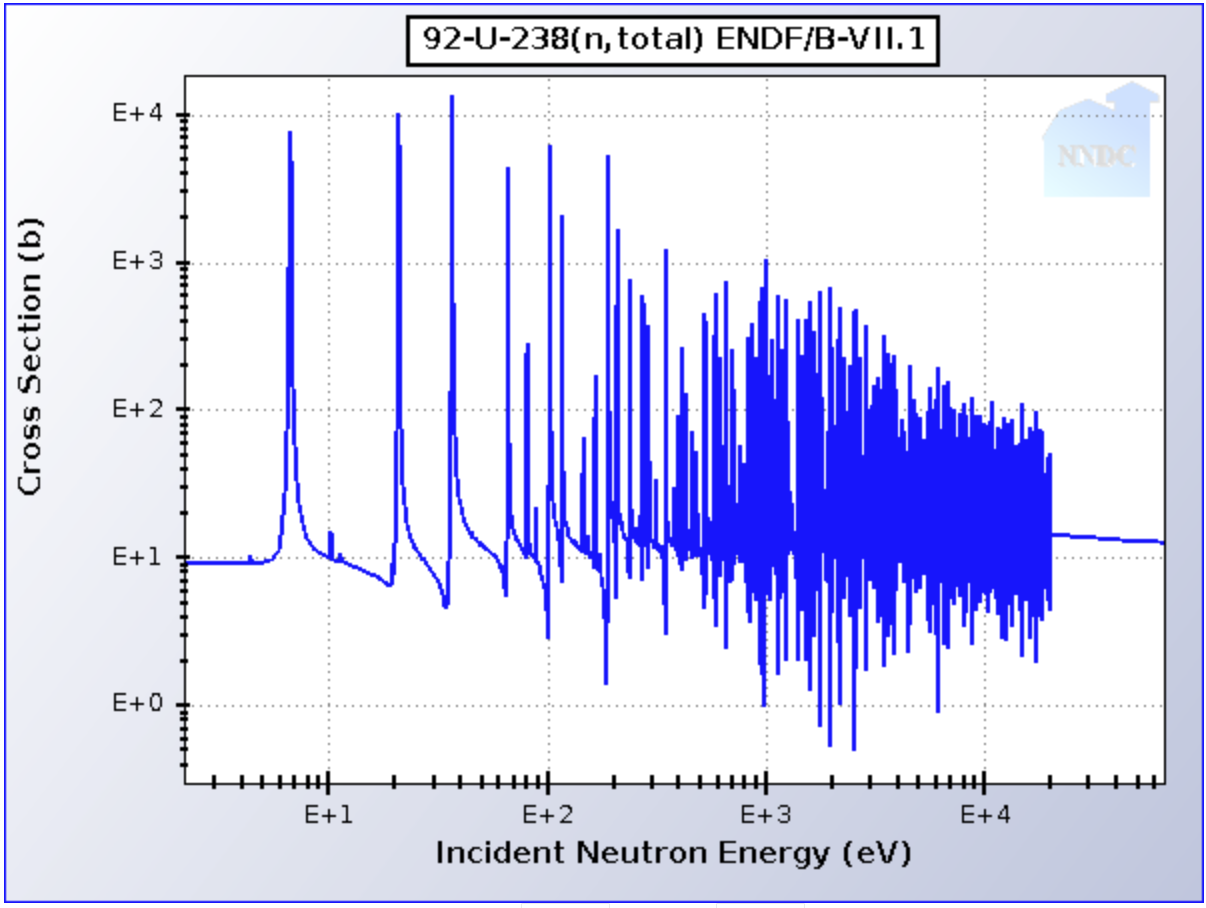
XSBench and RSBench solve the same problem, but use two different methods. One example of the underlying physical data looks like this for Uranium-238:
This is a very complicated function due to the resonances, which need to be accurately stored. The pointwise representation in XSBench is the simplest possible approach, where a table is stored with a very fine energy discretization and the cross section is stored at each energy point. In the above example, something like 100k energy points are stored. A cross section lookup in XSbench is therefore composed of sampling a random energy point, and then assembling data from many different nuclide pointwise tables like this. As each table is tabulated differently in energy, XSBench uses some different methods to accelerate the searching operations (e.g., unionized grid vs. logarithmic hash grid).
In RSBench, something more akin to a "curve fitting" approach is used to store the data; it is known as the windowed multipole representation. The resonances can each be described by quantum mechanics nicely, so we use the underlying physics equations to represent the resonances, combined with a background contribution from resonances farther away from a series of windows. This type of physics-based curve fit is much more efficient and/or accurate than using a more generic polynomial expansion. Thus, RSBench does not store pointwise data, but instead stores a few "residues" that describe each of the resonances (there are about 1000 resonances pictured above). A lookup then uses those residues to figure out what the cross section should be at that energy point, which in practice involves some fairly expensive FLOP operations (in particular, the Faddeeva function must be evaluated).
So good way to put it is "XSBench = more memory footprint, more memory lookups, less FLOP work" vs. "RSBench = less memory footprint, less memory lookups, more FLOP work."
The multipole method in RSBench is generally a newer approach. However, there are some complexities such that even when using multipole data, the multipole data is not available in certain regions of energy space such that a simulation will still have to do pointwise lookups a significant fraction of the time. So, both methods are important. OpenMC (a full MC app, which runs on ALCF Aurora at Argonne) uses both methods. Across the field, probably pointwise data is more commonly used as it's simpler to implement and has been around longer, but multipole is also seen as a more forward looking method as it is more likely to be able to scale on newer systems that have a system balance tiled more towards FLOP rates.
XSBench's input is completely described using cmdline parameters. We explain each parameter below in detail.
Usage: ./neutron xsbench [options] Options include: -m [simulation method] Simulation method (history, event) -t [threads] Number of OpenMP threads to run -s [size] Size of H-M Benchmark to run (small, large, XL, XXL) -g [gridpoints] Number of gridpoints per nuclide (overrides -s defaults) -G [grid type] Grid search type (unionized, nuclide, hash). Defaults to unionized. -p [particles] Number of particle histories -l [lookups] History Based: Number of Cross-section (XS) lookups per particle. Event Based: Total number of XS lookups. -h [hash bins] Number of hash bins (only relevant when used with "-G hash") -b [binary mode] Read or write all data structures to file. If reading, this will skip initialization phase. (read, write) -k [kernel ID] Specifies which kernel to run. 0 is baseline, 1, 2, etc are optimized variants. (0 is default.)
-t [threads]
Sets the number of OpenMP threads to run. The runcpu program will
automatically set the OpenMP environment variables to specify how many threads
XSBench should use. So, this parameter is just for debugging.
-m [simulation method]
Sets the simulation method, either "history" or "event". These options represent
the history based or event based algorithms respectively. The default is the
history based method. These two methods represent different methods of
parallelizing the Monte Carlo transport method. In the history based method, the
central mode of parallelism is expressed over particles, which each require some
number of macroscopic cross sections to be executed in series and in a dependent
order. The event based method expresses its parallelism over a large pool of
independent macroscopic cross section lookups that can be executed in any order
without dependence. The key difference between the two methods is the
dependence/independence of the macroscopic cross section loop. See the
"Transport Simulation Styles" section for more information.
-g [gridpoints]
Sets the number of gridpoints per nuclide. By default, this value is set to
11,303. This corresponds to the average number of actual gridpoints per
nuclide in the H-M Large model as run by OpenMC with the actual ACE ENDF
cross-section data. Note that this option will override the number of default
gridpoints as set by the '-s' option.
-G [grid type]
Sets the grid search type (unionized, nuclide,
hash). Defaults to unionized. The unionized grid is what is typically used in
Monte Carlo codes, as it offers the fastest speed. However, the increase in
speed comes with a significant increase in memory usage as a union of all the
separate nuclide grids must be formed and stored in memory. The "nuclide"
mode uses only the basic nuclide grid data, with no unionization. This is
slower as a binary search must be performed on every nuclide for each
macroscopic XS lookup, rather than only once when using the unionized grid.
Finally, the "hash" mode is a newer algorithm now used by many full Monte
Carlo codes which offers speed nearly equivalent to the unionized energy grid
method, but with only a small fraction of the memory overhead. See the "Cross
Section Lookup Methods" section for more details.
-s [size]
Sets the size of the Hoogenboom-Martin reactor model. There are four options:
'small', 'large', 'XL', and 'XXL'. By default, the 'large' option is selected.
The H-M size corresponds to the number of nuclides present in the fuel region.
The small version has 34 fuel nuclides, whereas the large version has 321 fuel
nuclides. This significantly slows down the runtime of the program as the data
structures are much larger, and more lookups are required whenever a lookup
occurs in a fuel material. Note that the program defaults to "Large" if no
specification is made. The additional size options, "XL" and "XXL", do not
directly correspond to any particular physical model. They are similar to the
H-M "large" option, except the number of gridpoints per nuclide has been
increased greatly. This creates an extremely large energy grid data structure
(XL: 120GB, XXL: 252GB), which is unlikely to fit on a single node, but is
useful for experimentation purposes on novel architectures.
-p [particles]
Sets the number of particle histories to simulate. By default, this value is set
to 500,000. Users may want to increase this value if they wish to extend the
runtime of XSBench, perhaps to produce more reliable performance counter data -
as extending the run will decrease the percentage of runtime spent on
initialization. Real MC simulations in a full application may use up to several
billion particles per generation, so there is great flexibility in this
variable.
-l [lookups]
Sets the number of cross-section (XS) lookups to perform per particle. By
default, this value is set to 34, which represents the average number of XS
lookups per particle over the course of its lifetime in a light water reactor
problem. Users should only alter this value if they are trying to capture the
behavior of a different type of reactor (e.g., one with a fast spectrum), where
the number of lookups per history may be different.
-h [hash bins]
Sets the number of hash bins (only relevant when using the hash lookup algorithm, as selected with "-G hash"). Default is 10,000.
-b [binary mode]
This optional mode can read or write the simulation data structures to disk.
Options are ("read" or "write"). This may be useful if it is necessary to
minimize the initialization phase of the program, which has a non-trivial
runtime. The generated file is named "XS_data.dat" and will be located in the
current working directory. The same file name and location will be used when
reading. Note that as the file is binary, it may not be portable between
compilers and computer systems. NOTE: When running in the "read" mode, you
must be running with an identical program configuration as when the file was
generated. E.g., if the file was generated with the "-G nuclide" argument,
subsequent runs reading from that file must use the same configuration flags.
For SPEC CPU, we attempted to use this mode to reduce runtime, but the side
effect was that time shifted into reading and writing the data file, which
is worse for a CPU benchmark, so we chose not to employ this method.
-k [kernel]
For some of the XSBench code-bases (e.g., openmp-threading and cuda) there are
several optimized variants of the main kernel. All source bases run basically
the same "baseline" kernel as default. Optimized kernels can be selected at
runtime with this argument. Default is "0" for the baseline, other variants are
numbered 1, 2, ... etc. People interested in implementing their own optimized
variants are encouraged to use this interface for convenience rather than
writing over the main kernel. The baseline kernel is defined at the top of the
"Simulation.c" source file, with the other variants being defined towards the
end of the file after a large comment block delineation. The optimized variants
are related to different ways of sorting the sampled values such that there is
less thread divergence and much better cache re-usage when executing the lookup
kernel on contiguous sorted elements. More details can be found in the
"Optimized Kernels" section.
RSBench's input is completely described using cmdline parameters. We explain each parameter below in detail.
Usage: ./neutron rsbench [options]
Options include:
-t [threads] Number of OpenMP threads to run
-m [simulation method] Simulation method (history, event)
-s [size] Size of H-M Benchmark to run (small, large)
-l [lookups] Number of Cross-section (XS) lookups per particle history
-p [particles] Number of particle histories
-P [poles] Average Number of Poles per Nuclide
-W [poles] Average Number of Windows per Nuclide
-d Disables Temperature Dependence (Doppler Broadening)
-k [kernel] Enable an alternative computation kernel
-t [threads]
Sets the number of OpenMP threads to run. The runcpu program will
automatically set the OpenMP environment variables to specify how many threads
RSBench should use. So, this parameter is just for debugging.
-m [simulation method]
Sets the simulation method, either "history" or "event". These options represent
the history based or event based algorithms respectively. The default is the
history based method. These two methods represent different methods of
parallelizing the Monte Carlo transport method. In the history based method, the
central mode of parallelism is expressed over particles, which each require some
number of macroscopic cross sections to be executed in series and in a dependent
order. The event based method expresses its parallelism over a large pool of
independent macroscopic cross section lookups that can be executed in any order
without dependence. They key difference between the two methods is the
dependence/independence of the macroscopic cross section loop. See the
"Transport Simulation Styles" section for more information.
-s [size]
Sets the size of the Hoogenboom-Martin reactor model. There are four options:
'small', 'large', 'XL', and 'XXL'. By default, the 'large' option is selected.
The H-M size corresponds to the number of nuclides present in the fuel region.
The small version has 34 fuel nuclides, whereas the large version has 321 fuel
nuclides. This significantly slows down the runtime of the program as the data
structures are much larger, and more lookups are required whenever a lookup
occurs in a fuel material. Note that the program defaults to "Large" if no
specification is made. The additional size options, "XL" and "XXL", do not
directly correspond to any particular physical model. They are similar to the
H-M "large" option, except the number of gridpoints per nuclide has been
increased greatly. This creates an extremely large energy grid data structure
(XL: 120GB, XXL: 252GB), which is unlikely to fit on a single node, but is
useful for experimentation purposes on novel architectures.
-p [particles]
Sets the number of particle histories to simulate. By default, this value is set
to 500,000. Users may want to increase this value if they wish to extend the
runtime of RSBench, perhaps to produce more reliable performance counter data -
as extending the run will decrease the percentage of runtime spent on
initialization. Real MC simulations in a full application may use up to several
billion particles per generation, so there is great flexibility in this
variable.
-l [lookups]
Sets the number of cross-section (XS) lookups to perform per particle. By
default, this value is set to 34, which represents the average number of XS
lookups per particle over the course of its lifetime in a light water reactor
problem. Users should only alter this value if they are trying to capture the
behavior of a different type of reactor (e.g., one with a fast spectrum), where
the number of lookups per history may be different.
-P [poles]
Sets the average number of poles per nuclide.
-w [windows]
Sets the number of windows per nuclide.
-d
This flag disables Doppler broadening, in effect making it single temperature 0K
simulation. Doppler broadening is enabled by default. While Doppler broadening
is likely to be used in most cases in a full application like OpenMC, in may be
useful to disable in some cases so as to compare to traditional single
temperature lookup algorithms.
-k [kernel]
For some of the RSBench code-bases (e.g., openmp-threading and cuda) there are
several optimized variants of the main kernel. All source bases run basically
the same "baseline" kernel as default. Optimized kernels can be selected at
runtime with this argument. Default is "0" for the baseline, other variants are
numbered 1, 2, ... etc. People interested in implementing their own optimized
variants are encouraged to use this interface for convenience rather than
writing over the main kernel. The baseline kernel is defined at the top of the
"Simulation.c" source file, with the other variants being defined towards the
end of the file after a large comment block delineation. The optimized variants
are related to different ways of sorting the sampled values such that there is
less thread divergence and much better cache re-usage when executing the lookup
kernel on contiguous sorted elements. More details can be found in the
"Optimized Kernels" section.
The XSBench and RSBench applications print out results along with a verification step. For the benchmark to pass, this output must match exactly to the expected output. More info on the verification is given below.
Both XSBench and RSBench generate a hash of the results at the end of the simulation, and display it once the code has completed executing. This hash can then be verified against hashes that other versions or configurations of the code generate. For instance, running XSBench with 4 threads vs 8 threads (on a machine that supports that configuration) will generate the same hash value. Changing the model / run parameters is expected to generate a totally different hash number (i.e., increasing the number of particles, number of gridpoints, etc, will result in different hashes). Changing the simulation mode (history or event) will generate different hashes. However, changing the type of lookup performed (e.g., nuclide, unionized, or hash) should result in the same hash being generated. Since the benchmark cmdlines are fixed, this facilitates verification across systems.
In order to additionally help improve verification and debugging, SPEC samples the maximum values for particle transport and prints them to stdout. The sampling may be a single value or a summation of values depending on the algorithm being used. The sample size varies by the input size. The sampling ensures intermediate results are correct without having to print all values which can be very large.
C
The benchmark uses OpenMP threading.
None. Program is only C code, and the CUDA options have been stripped away for SPEC CPU.
XSBench sources are available at github.com/ANL-CESAR/XSBench. The SPEC CPU code started with the snapshot at git hash 6e2beb7 from that repository.
RSBench sources are available at github.com/ANL-CESAR/RSBench. The SPEC CPU code started with the snapshot at git hash 7848d0e from that repository.
Both XSBench and RSBench are distributed under the MIT license.
Copyright © 2026 Standard Performance Evaluation Corporation (SPEC®)